مقدمه
افزایش چشمگیر حجم داده ها زیرساخت های فناوری اطلاعات شرکت را تحت فشار شدید قرار می دهد. از منظر هزینه ، عملکرد ، مقیاس پذیری و مدیریت. استفاده از روشهای کارآمدتر ذخیره و مدیریت داده ها برای پاسخگویی به تقاضاهای فزاینده ای که برای سیستم های فن آوری اطلاعات وجود دارد ، ضروری شده است.
مقدار داده هایی که شرکت ها ذخیره و مدیریت می کنند به سرعت در حال رشد است. برآوردهای مختلف صنعت نشان می دهد که هر ۲ تا ۳ سال حجم داده ها دو برابر می شود. رشد سریع داده ها ، چه از نظر هزینه و چه از نظر عملکرد ، چالش های دلهره آور فناوری اطلاعات را به همراه دارد.
اگرچه هزینه ذخیره سازی مدام در حال کاهش است ، اما حجم داده های با رشد سریع ، ذخیره سازی را به یکی از پرهزینه ترین عناصر اکثر بودجه های فناوری اطلاعات تبدیل می کند. علاوه بر این ، رشد شتاب داده ها باعث می شود
در حین ماندن در بودجه ، تأمین نیازهای عملکرد و کارایی نیز دشوار شود.
اگرچه مدت هاست که اکثر سازمان ها داده های خود را به عنوان یکی از با ارزش ترین دارایی های شرکتی خود می دانند ، اما اخیراً مقدار داده های تحت مدیریت به یک موضوع مهم تبدیل شده است. در ابتدا از داده ها برای دستیابی به اهداف عملیاتی برای راه اندازی کسب و کار استفاده می شد ، اما با رشد قابلیت های فناوری ، پایگاه های اطلاعاتی بزرگتر برای برنامه های عملیاتی ( OLTP ) و تحلیلی ( Data Warehouse) عملی شده اند.
نیازمندیهای مختلف، نحوه و دلیل نگهداری اطلاعات را تغییر می دهد ، زیرا بسیاری از سازمان ها اکنون مجبور به نگهداری و کنترل اطلاعات بیشتر برای مدت زمان طولانی تر هستند. این نیازمندیها اغلب فراتر از داده های ساختاریافته به طور معمول در پایگاه داده های رابطه ای مانند پایگاه داده اوراکل ذخیره می شوند. اطلاعات نیمه ساختار یافته و داده های بدون ساختار نیز مانند تصاویر پزشکی ، فیلم ها ، عکس ها ، قراردادها ، اسناد و غیره به نگهداری اطلاعات اضافه شده اند در نتیجه انفجار حجم داده ها یکی از چالش های سازمانها برای سازماندهی ، مدیریت و ذخیره سازی آنهامنجر شده است.
سازمان ها سعی می کنند مقادیر سریع در حال رشد داده را با کمترین هزینه ممکن ذخیره کنند.پایگاه داده اوراکل از نسخه ۱۲c به بعد شامل مجموعه ای از ویژگی های غنی است که می تواند به پیاده سازی راهکار مدیریت چرخه زندگی اطلاعات کمک کند.این ویژگی ها شامل:
پارتیشن بندی داده ها
- فشرده سازی پیشرفته رکورد (Advanced Row Compression )
- فشرده سازی ترکیبی ستون (Hybrid Columnar Compression )
- بهینه سازی خودکار داده ها (Automatic Data Optimization )
- نقشه حرارت ( Heat Map )
- بایگانی اطلاعات درون پایگاه داده ( In-database Archiving)
- استفاده از داده ها با نوع SecureFiles
طبقه بندی ذخیره سازی و طبقه بندی فشرده سازی
یک شرکت (یا حتی یک برنامه منفرد) به همه داده های خود به یک اندازه دسترسی ندارد. مهمترین داده ها یا داده هایی که اغلب به آنها دسترسی پیدا می کنند به بهترین عملکرد و در دسترس بودن نیاز دارند. ارائه بهترین کیفیت دسترسی به همه داده ها هزینه بر ، ناکارآمد و غالباً غیر ممکن است.
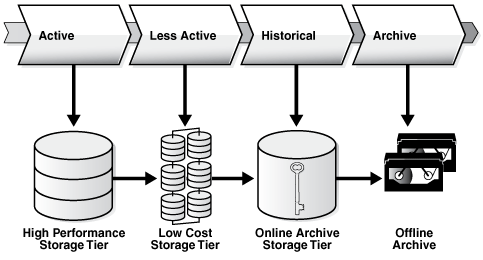
سازمان های فن آاوری اطلاعات طبقه بندی ذخیره سازی را اجرا می کنند.با طبقه بندی ذخیره سازی ، سازمان ها می توانند داده های خود را در طبقات مختلف ذخیره سازی نگهداری کنند.
دسترسی به داده ها را به سه دسته تقسیم بندی می کنند:
- دسترسی بالا یا داغ (Hot)
- در این حالت اطلاعات بطور دایم در حال نوشتن و خواندن و تغییر کردن هستند
- دسترسی متوسط یا گرم (Warm)
- در این حالت تغییرات داده بندرت اتفاق می افتد.
- دسترسی پایین یا سرد (Cold)
در این حالت داده هب به مدت طولان تغییر نمی کنند.
اجازه بدهید برای فهم بیشتر به دو برنامه کاربردی که این روزها در بیشتر سازمانها استفاد می شود اشاره کنیم.
- اتوماسیون اداری
در این سامانه که برای تولید نامه و گردش آن در سازمان استفاده می شود. این سامانه از اطلاعات رابطه ای ساختار یافته مانند جدول نامه بعنوان پدر و جداول اقدام کنندگان بعنوان فرزند، و اطلاعات ساختار نیافته مانند پیوست نامه که شامل عکس، فیلم، فایل در قالب PDF, DOC و غیره استفاده می شود
- سامانه مالی
این سامانه را نیز می توان شبیه سامانه اتوماسیون اداری فرض کرد.
در هر دوی این سامانه ها اطلاعات مختلفی نگهداری می شود ولی دسترسی به اطلاعات به مدت زمان نگهداری داده نیز بستگی دارد. فرض کنید این سامانه های برای چندین سال در سازمانها استفاده می شوند حال بعد از گذشت چند سال دسترسی به اطلاعات سال جاری با دسترسی به اطلاعات دو یا سه قبل بسیار متفاوت می باشد.
کاربران سامانه بطور دایم به اطلاعات سال جاری نیاز دارند و آنها را تغییر می دهند، جستجو می کنند و یا گزارش تهیه می کنند. در صورتی دسترسی به اطلاعات سال های قبل بندرت اتفاق می افتد.بر این اساس سازمانها نیاز دارند اطلاعات قدیمی را به فقط خواندی (Read Only) تغییردهند و یا حتی آنها را برای تحلیل به سامانه های warehouse انتفال دهند.
پس نگهداری تمامی اطلاعات سال های مختلف براساس دسترسی به آنها در یک طبقه ذخیره سازی مقرون بصرفه نمی باشد.
بطور کل دیسکهای ذخیره سازی را می توان به سه دسته کلی تقسیم کرد.
- پر سرعت، ظرفیت پایین، پر هزینه مانند دیسکهای SSD (Solid State Disk)
- سرعت متوسط، ظرفیت متوسط، هزینه مناسب مانند دیسکهای SAS
- سرعت پایین، ظرفیت بالا، کم هزینه مانند دیسکهای SATA
با طبقه بندی بالا و نحوه دسترسی به اطلاعات برای مقرون بصرفه بودن استفاده از ذخیره سازها باید بصورت زیر عمل کرد.
دسترسی بالا به اطلاعات و یا داده های داغ بر روی دیسکها با سرعت بالا قرار گیرند.
دسترسی متوسط به اطلاعات و یا داده های گرم بر روی دیسکها با سرعت متوسط قرار گیرد.
دسترسی کم به اطلاعات و یا داده های سرد بر روی دیسکها با سرعت پایین قرار گیرد.
شکل زیر نحوه طبقه بندی ذخیره سازی برای اطلاعات مختلف بر حسب دسترسی را نشان می دهد.

استفاده از از این روش برای طبقه بندی داده ها و انتقال آن بر روی دیسکهای مختلف و نحوه فشرده سازی اطلاعات را مدیریت چرخه زندگی اطلاعات و یا Information Life-cycle Management (ILM) گویند.
مدیریت چرخه زندگی اطلاعات
مدیریت چرخه زندگی اطلاعات (ILM) با توجه به نیازهای فعلی و عملکرد شرکت ، با ذخیره سازی داده ها در طبقات مختلف ذخیره سازی و فشرده سازی ، این چالش ها را برطرف می کند. این روش امکان بهینه سازی فضای ذخیره سازی را برای دو منظور از لحاظ هزینه یعنی پس انداز و بالاترین عملکرد را فراهم می کند.
به طور کلی ، پنج مرحله برای اجرای یک استراتژی ILM وجود دارد:
۱– طبقه بندی داده ها را تعریف کنید:
برای پایگاه های داده اصلی که کسب و کار شما را هدایت می کنند ، انواع داده ها و محل ذخیره سازی آن را در پایگاه داده مشخص کنید و سپس موارد زیر را تعیین کنید.
- کدام داده مهم است ، کجاست و چه چیزی باید نگهداری شود.
- چگونه این داده ها درون سازمان جریان می یابند.
- با گذشت زمان چه اتفاقی برای این داده ها می افتد و چه زمانی غیر فعال می شوند.
- درجه دسترسی به اطلاعات و حفاظت از آنها چگونه است.
- نگهداری اطلاعات برای نیازهای قانونی و تجاری چگونه است.
۲–ایجاد طبقه بندی منطقی ذخیره سازی:
داده ها و نگهداری آنها را در طبقه های مختلف ذخیره سازی مشخص کنید.
۳–چرخه زندگی اطلاعات را تعریف کنید:
چگونگی انتقال داده ها از در طبقات مختلف ذخیره سازی ، نحوه فشرده سازی و مدت زمان نگهداری داده ها در هر طبقه را مشخص کنید. به طور خلاصه ، یک چرخه زندگی مشخص می کند که داده ها در کجا ذخیره شوند ، نحوه ذخیره داده ها و مدت زمان نگهداری داده ها چقدر است.
۴–یک چرخه عمر برای جدول و پارتیشن های آن در پایگاه داده مشخص کنید.
۵–سیساتهای چرخه زندگی را تعریف و اجرا کنید
خودکار کردن ILM با پایگاه داده اوراکل
معمولاً سازمان ها برای پیاده سازی استراتژی ILM در نسخه ۱۱g ، از راهکار Advanced Compression and Data Partitioning بصورت دستی برای ایجاد و اسقرار فشرده سازی و طبقه بندی ذخیره سازی استفاده می کنند، راه حلی که سازمان ها را مجبور به درک دقیق از دسترسی به داده ها و الگوهای استفاده در برنامه ها و جداول و پارتیشن ها می کند.
بر اساس این بینش ، مدیران پایگاه داده ، بهمراه همتایان ذخیره سازی خود ، می توانند به صورت دستی داده ها را بر اساس بهترین تخمین های مربوط به استفاده واقعی از داده ها،آنها را فشرده و یا انتقال دهند ، در حالت ایده آل سعی بر آن است که اطمینان حاصل کنیم، داده های بابیشترین دسترسی در ذخیره سازی با کارایی بالاتر باقی بماند.
ولی این موضوع پر چالشی برای مدیران پایگاه داده است که بطور دایم باید عملیات دستی در زمانهای مختلف انجام بدهند. بنابراین ایده آل ترین راهکا،ر استفاده خودکار از ILM است.
نقشه حرارتی و بهینه سازی خودکار داده ها
برای کمک به خودکارسازی ILM دو ویژگی به اوراکل نسخه ۱۲c به بعد اضافه شده است.
- نقشه حرارتی (Heat Map)
- بهینه سازی خودکار داده (ADO) Automatic Data Optimization
هر دو این ویژگی ها بخشی از گزینه Oracle Advanced Compression هستند.
نقشه حرارتی و یا Heat Map
همانطور در قبل اشاره شد نحوه دسترسی به داده ها به سه دسته داغ،گرم و سرد طبقه بندی شد و بر این اساس برای داده ها یک نقشه حرارتی تهیه می شود.
در شکل زیر طبقه بندی دسترسی اطلاعات نمایش داده شده است.

Heat Map به طور خودکار استفاده اطلاعات را در سطح رکورد و segment ردیابی می کند.در زمان ویرایش داده ها،آن را درسطح رکورد و در سطح بلوک یکپارچه می کند، و زمان های ویرایش ، زمان اسکن کامل جدول ، و زمان مراجعه به ایندکس در سطح segment ردیابی می کند.
Heat Map امکان مشاهده جزئی از نحوه دستیابی به داده ها و چگونگی تغییر الگوهای دسترسی را با گذشت زمان فراهم می کند.دسترسی برنامه ای به داده های Heat Map از طریق مجموعه ای از توابع جدول PL / SQL و همچنین از طریق ویوهای دیکشنری قابل دسترس است.
در شکل زیر یک روش برای به تصویر کشیدن داده های نقشه حرارتی را نشان می دهد. هر کادر نشان دهنده یک پارتیشن از یک جدول است. اندازه جعبه اندازه نسبی پارتیشن است و رنگ نشان می دهد که پارتیشن بر اساس جدیدترین دسترسی به هر ردیف در پارتیشن “داغ” (یعنی به طور مکرر قابل دسترسی است) است.

علاوه بر این ، Oracle Enterprise Manager نمایش های گرافیکی داده های نقشه حرارتی را ارائه می دهد.

بهینه سازی خودکار داده ها (Automatic Data Optimization)
بهینه سازی خودکار داده ها (ADO) به سازمان ها اجازه می دهد سیاست هایی برای فشرده سازی داده ها و انتقال آنها ایجاد کنند و طبقه بندی خودکار فشرده سازی و ذخیره سازی را انجام دهند. پایگاه داده اوراکل سیاست های ADO تعریف شده توسط مدیر پایگاه داده را در بازه های زمانی ارزیابی می کند و از اطلاعات جمع آوری شده توسط Heat Map برای تعیین اینکه کدام عملیات را انجام دهد استفاده می کند. تمام عملیات ADO بدون دخالت کاربر به طور خودکار و در پس زمینه اجرا می شود.
سیاست های ADO را می توان در سطح segment و یا رکورد برای جداول و پارتیشن ها مشخص کرد. علاوه بر ارزیابی اجرای خورکار که در بازه زمانی خاص تعریف شده، می تواند در هر زمان توسط مدیر پایگاه داده به صورت دستی یا از طریق اسکریپت اجرا شود. سیاست های ADO مشخص می کند که در چه شرایطی (دسترسی به داده ها) عملیات ADO آغاز شود.
زمان های اجرای عملیات ADO مانند عدم دسترسی، عدم تغییر و یا زمان ایجاد داده تعیین می شود. به عنوان مثال ، پس از n روز یا ماه یا سال. همچنین مدیر پایگاه داده می تواند شرایط سفارشی سیاست را ایجاد کند و به این ترتیب امکان تعیین عوامل دیگر درزمان انتقال یا فشرده سازی داده هارا نیز فراهم کند.
طبقه بندی فشرده سازی
ADO هم از طبقه بندی فشرده سازی در سطح رکورد و هم از طبقه بندی فشرده سازی در سطح segment پشتیبانی می کند. سیاست ها می تواند با روش فشرده سازی رکورد( Advanced Row Compression) و یا فشرده سازی ستونی ترکیبی (Hybrid Columnar Compression) رکوردهای غیر فعال را در سطح بلاک ها و یا در سطح segment ها فشرده سازی کند.
این قابلیت وجود دارد که با روش فشرده سازی رکورد( Advanced Row Compression) و یا پرس و جو انباره (Query Warehouse) و یا فشرده سازی ستونی ترکیبی (Hybrid Columnar Compression) ترکیبی از داده های فشرده شده و یا نشده را در segment نگهداری کرد.
تمام اقدامات فشرده سازی توسط ADO کاملاً آنلاین هستند و هیچ تاثیری در پرس و جوها و تراکنش های OLTP ندارد.
طبقه بندی ذخیره سازی
ADO از طبقه بندی ذخیره سازی در سطح tablespace و پایگاه داده پشتیبانی می کند. همانطور که یک tablespace به یک درصد ازاستفاده برسد سیاست ADO داده های segment را به یک tablespace دیگر اتنقال می هد.
هنگامی که فضای موجود در tablespace اصلی آزاد بشود، دیگر هیچ داده ای جابجا نمی شود. این یک حرکت یک طرفه است و از ویژگی انتقال پارتیشن آنلاین اوراکل ۱۲c استفاده می کند،این عملیات باعث قطعی و یا زمان خاموشی برنامه های کاربردی نمی شو و کسب و کار ادامه خواهد داشت.
پیاده سازی ILM با Oracle Database 12c
در هسته راهکار Oracle Database ILM قابلیت تعریف چندین طبقه داده و طبقه بندی ذخیره سازی و اختصاص بخش های مختلف داده بر اساس هزینه ، کارایی و امنیت مورد نظر برای هر بخش وجود دارد.
این کار با استفاده از پارتیشن بندی داده ها، فشرده سازی پیشرفته رکورد ، و فشرده سازی ستونی ترکیبی که به طور خلاصه در زیر شرح داده شده است ، فعال می شود.
پارتیشن بندی داده ها
در ابتدایی ترین سطح ، مدیران فن اوری اطلاعات می توانند با تقسیم بندی داده ها بر اساس سن داده ها و سپس انتقال پارتیشن های قدیمی به دیسکهای کم هزینه، ضمن حفظ پارتیشن های فعال در دیسکها با سرعت بالاتر، یک استراتژی مدیریت چرخه زندگی اطلاعات (ILM) را پیاده سازی کنند.
پارتیشن بندی داده اجازه می دهد تا یک جدول ، ایندکس یا idex-organized tabble (IOT) به قطعات کوچکترتقسیم شوند. هر قطعه از یک شی پایگاه داده، پارتیشن نامیده می شود. هر پارتیشن نام خاص خود را دارد و ممکن است به صورت اختیاری ویژگی های ذخیره سازی خاص خود را داشته باشد. از دیدگاه مدیر پایگاه داده ، یک شی پارتیشن بندی شده دارای چندین قطعه است که می تواند به صورت جمعی یا جداگانه مدیریت شود. این امر به
مدیر انعطاف پذیری قابل توجهی در مدیریت شی پارتیشن بندی شده می دهد. با این حال ، از دیدگاه برنامه های کاربردی، آن را بصورت یک جدول پارتیشن نشده می بیند و هیچ تغییری در برنامه های کاربردی نیاز نیست.
پارتیشن بندی، عملکرد پرس و جوها را بهبود و یا عملیات نگهداری را فراهم می کند. علاوه بر این،پارتیشن بندی می تواند هزینه کل مالکیت داده ها را تا حد زیادی کاهش دهد ، و یک روش “بایگانی طبقه بندی ” را برای نگهداری اطلاعات قدیمی تر، در حالیکه به اطلاعات آنلاین وابستگی دارند را در دیسکها با هزینه پایین تر فراهم می کند.
فشرده سازی پیشرفته رکورد Advanced Row Compression
فشرده سازی پیشرفته رکورد ، از یک الگوریتم فشرده سازی منحصر به فرد استفاده می کند که به طور خاص برای کار با جداول پایگاه داده در انواع برنامه ها طراحی شده است. الگوریتم با حذف مقادیر تکراری در یک بلوک پایگاه داده ، حتی در چندین ستون ، کار می کند.
نسبت فشرده سازی بدست آمده با یک مجموعه داده به ماهیت داده های فشرده شده بستگی دارد. به طور کلی ، سازمان ها می توانند انتظار داشته باشند که با استفاده از فشرده سازی پیشرفته رکورد ، فضای ذخیره سازی خود را ۲ تا ۴ برابر کاهش دهند. یعنی مقدار فضا مصرف شده توسط داده های فشرده شده دو تا چهار برابر کوچکتر از داده های مشابه بدون فشرده سازی خواهد بود.
فشرده سازی ستونی ترکیبی Hybrid Columnar Compression (HCC)
فشرده سازی ستونی ترکیبی سطح بالاتری از فشرده سازی داده ها را فراهم می کند و باعث کاهش هزینه های هنگفت شرکت ها می شود.متوسط نسبت فشرده سازی می تواند از ۶ تا ۱۵ برابر باشد.
معیارهای مشتری در دنیای واقعی منجر به صرفه جویی در ذخیره سازی تا ۵۰ برابر و حتی بیشتر شده است.
فن آوری فشرده سازی ستونی ترکیبی اوراکل از ترکیبی از روش های سطری و ستونی برای ذخیره سازی داده ها استفاده می کند. در حالی که داده های فشرده HCC می توانند با استفاده از عملکردهای متداول دستورات DML مانند INSERT ، UPDATE و DELETE ، ویرایش شوند. HCC برای داده هایی که تغییر نمی کنند و یا بندرت تغییر می کنند،مناسب است.
سطح فشرده سازی HCC
فشرده سازی انبار HCC (همچنین به عنوان فشرده سازی پرس و جو شناخته می شود) در ذخیره سازی Exadata بهینه شده است. با استفاده از تعداد کمتری از بلوک های دیسک ، عملکرد جستجوی اسکن را افزایش دهید. فشرده سازی بایگانی HCC برای به حداکثر رساندن پس انداز ذخیره سازی بهینه شده است ، به طور معمول نسبت فشرده سازی ۱۵ برابر شده است.
فشرده سازی ستونی ترکیبی برای استفاده در Exadata ، SuperCluster ، Pillar Axiom ، FS1 و Sun ZFS Storage موجود است. برای استفاده از HCC نیازی به لایسنس اضافی نیست.
در شکل زیر انواع و نسبت فشرده سازی نمایش داده شده است.

مثال پیاده سازی پایگاه داده Oracle 12c ILM
در ادامه این سند نحوه استفاده از ویژگی ها و گزینه های Oracle Database 12c برای اجرای این پنج مورد بحث خواهد شد. مراحل استراتژی ILM قبلاً در این سند تعریف شده است. این مراحل در مورد چگونگی و محل قرارگیری آنها در یک مرحله بررسی می شود
راه حل ILM پایگاه داده اوراکل، همچنین ویژگی ها و گزینه های پایگاه داده اوراکل می تواند مورد استفاده قرار گیرد.
مراحل ۱ تا ۳: تعریف طبقه های داده ، تعیین طبقه بندی منطقی ذخیره سازی و اطلاعات مربوط به چرخه زندگی :
طبقه های داده را تعریف کنید
این مرحله شامل بررسی تمام داده های سازمان شما است. این تحلیل نیاز به بررسی و درک سازمان ها دارد
که کدام اشیا با کدام برنامه ها مرتبط هستند ، این اشیا در کجا قرار دارند (در چه طبقه ای از ذخیره سازی) ،
آیاپارتیشن و یا فشرده شده اند.
ایجاد طبقه بندی منطقی ذخیره سازی
این مرحله با استفاده از ذخیره سازی با کارایی بالا و هزینه بالاتر و ذخیره سازی با ظرفیت بالا و هزینه کمتر ، طبقه بندی ذخیره سازی را شناسایی و ایجاد می کنید.
چرخه زندگی را تعریف کنید
چگونگی انتقال داده ها از طریق طبقه بندی های ذخیره سازی طول عمرداده را مشخص می کند. تعریف چرخه زندگی شامل یک یا چند مرحله است که یک طبقه بندی ذخیره سازی ، ویژگی های داده مانند فشرده سازی و یا فقط خواندنی ، و مدت زمان نگهداری داده های مربوط به آن مرحله چرخه زندگی را انتخاب می کند.
چرخه زندگی اطلاعات و فعالیتهای گرد آوری شده گامهای ۱ و ۲ به مدیر پایگاه داده گزینه های زیر را اجازه میده تا برای آنهابرنامه ریزی کند.
محل ذخیره اطلاعات ( طبقه بندی منطقی ذخیره سازی)
نحوه ذخیره داده ها (پارتیشن بندی و فشرده سازی داده ها)
مدت زمان نگهداری داده ها
تعیین چگونگی فشرده سازی داده ها
با استفاده از برنامه ریزی مرحله ۳ ، شکل زیر نشان می دهد که چگونه می توان فعال ترین داده ها را در یک سطح با عملکرد بالا قرار داد و داده های کم سابقه و قدیمی را در طبقات با هزینه پایین ترقرار داد.
با استفاده از ویژگی پارتیشن بندی داده، فعال ترین پارتیشن های داده را می توان در ذخیره سازی سریعتر و با کارایی بالاتر قرار داد ، در حالی که کم فعال ترین پارتیشن ها و داده های قدیمی را می توان در ذخیره سازی با هزینه کمتر قرار داد. و می توان فشرده سازی داده ها را به صورت دلخواه بطور پارتیشن به پارتیشن انجام داد.
باترکیب این ویژگی ها، کسب و کار می تواند نیازمندیهای کارایی، قابلیت اطمینان و امنیت خود را برآورده کند.
در برنامه های که تراکنشی (OLTP) هستند ، سازمان ها می توانند برای فعال ترین جداول و پارتیشن ها از Advanced Row Compression (که قبلاً به آن فشرده سازی جدول OLTP گفته میشد) استفاده کنند تا اطمینان حاصل کنند که هنگامی که داده های جدیدی اضافه می شوند و یا به روز می شوند با انجام عملیات DML در برابر جداول و پارتیشن های فعال، فشرده می شوند. برای داده های سرد یا قدیمی در جداول OLTP ، سازمان ها می توانند از Warehouse یا فشرده سازی ستونی ترکیبی بایگانی (Archive Hybrid Columnar Compression) با فرض اینکه آنها از فضای ذخیره سازی پشتیبانی می کنند، استفاده کنند.

- قبل از پایگاه داده اوراکل ۱۲c ، سازمان ها باید هر دو طبقه بندی ذخیره سازی و طبقه بندی فشرده سازی داده های خود را بر اساس دانش آنها از پایگاه داده به صورت دستی اجرا کنند. با استفاده از پایگاه داده ۱۲c به بعد، طبقه بندی فشرده سازی و ذخیره سازی می تواند به صورت خودکار انجام شود و باعث کاهش نیازمندیهای سازمانها برای داشتن بینش عمیق دسترسی و الگوهای استفاده از داده ها می شود. اکنون می توان این اطلاعات را توسط خود پایگاه داده ، با استفاده از قابلیت Advanced Compression Heat Map ، و سیاستهای ILM به طور خودکار توسط پایگاه داده با استفاده از بهینه سازی خودکار (ADO) انجام شود.
- مراحل ۴ و ۵: تخصیص چرخه زندگی به جداول و پارتیشن ها و تعریف و اجرای سیاست ها
- اجرای یک راه حل طبقه بندی خودکار فشرده سازی و ذخیره سازی با استفاده از بهینه سازی خودکار داده و Heat Map ساده است ، همانطور که مثال زیر نشان می دهد.این مثال یک سیاست چرخه عمر اطلاعات را برای جدول ORDERS با هدف فشرده سازی جدول برای فعالیت OLTP فراهم می کند و سپس هنگامی که جدول کمترین فعالیت را دارد (تغییرات کم یا بدون تغییر اما پرس و جوی فعال) جدول را با استفاده از HCC فشرده می کنیدوقتی داده ها، دیگر فعالانه مورد پرس و جو قرار نمی گیرند ، اما باید آنها در دسترس باشد مانند داده های قدیمی، سپس با استفاده از فشرده سازی HCC ARCHIVE جدول را حتی بیشتر فشرده کنید و به طبقه بندی ذخیره سازی با کمترین هزینه ببرید.
قبل از هر چیز باید پارامتر heat_map را در سطح CDB برای همه پایگاه داده و یا در سطح یک PDB فعال کنید.
CONN / AS SYSDBA
ALTER SESSION SET CONTAINER = pdb1; ALTER SYSTEM SET heat_map = ON; CREATE USER test IDENTIFIED BY test QUOTA UNLIMITED ON users; GRANT CREATE SESSION, CREATE TABLE TO test;
ایجاد tablespace های مختلف بر روی دخیره سازی های مختلف مانند SSD, SAN,SATA
دیسکهای پر سرعت با هزینه بالا:
CREATE TABLESPACE fast_storage_ts DATAFILE SIZE 1M AUTOEXTEND ON NEXT 1M; CREATE TABLESPACE fast_storage_idx_ts DATAFILE SIZE 1M AUTOEXTEND ON NEXT 1M;
دیسکهای سرعت متوسط با هزینه متوسط:
CREATE TABLESPACE medium_storage_ts DATAFILE SIZE 1M AUTOEXTEND ON NEXT 1M;
دیسکهای کم سرعت با هزینه پایین:
CREATE TABLESPACE slow_storage_ts DATAFILE SIZE 1M AUTOEXTEND ON NEXT 1M; CREATE TABLESPACE slow_storage_idx_ts DATAFILE SIZE 1M AUTOEXTEND ON NEXT 1M;
- مثال اول:سیاست فشرده سازی سطح ADO برای فشرده سازی خودکار با استفاده از فشرده سازی پیشرفته رکورد پس از عدم تغییر برای ۳۰ روز ایجاد شده است. این به طور خودکار فضای ذخیره سازی مورد استفاده در داده های فروش قدیمی را کاهش می دهد و همچنین عملکرد پرس و جوهایی را که از طریق تعداد زیادی رکوردها در پارتیشن های قدیمی جدول اسکن می کنند ، بهبود می بخشد.
ALTER TABLE orders ILM ADD POLICY
ROW STORE COMPRESS ADVANCED SEGMENT AFTER 30 DAYS OF NO MODIFICATION;
- مثال دوم:سیاست ADO در سطح segment برای فشرده سازی خودکار، با استفاده از فشرده سازی ستون ترکیبی پس از عدم تغییر برای ۹۰ روز ایجاد شده است. وقتی داده ها دیگر به روز نمی شوند ، اما همچنان مورد پرسش قرار می گیرند. انتقال به HCC باعث صرفه جویی در فضای ذخیره سازی می شود و باعث افزایش عملکرد پرس و جو می شود.
ALTER TABLE orders ILM ADD POLICY COLUMN STORE COMPRESS FOR QUERY HIGH SEGMENT AFTER 90 DAYS OF NO MODIFICATION; |
- مثال سوم:سازمان مزایای فشرده سازی را می خواهد ، اما همچنین باید اطمینان حاصل کند که الزامات SLA را برآورده می کند. فشرده سازی داده ها بر اساس بلوک به بلوک به جای کلsegmentمفید خواهد بود. می توانید سیاست ADO را در سطح رکورد ایجاد کنید تا بطور خودکار بلوک ها را فشرده کند ، پس از اینکه هیچ رکوردی در یک بلوک برای حداقل ۳ روز ویرایش نشود با سیاست هایADO در سطح رکورد ، همه رکورد های موجود در بلوک فشرده شوند.در این مثال رکوردها در هنگ م ورود فشرده نمی شوند و به جای کلمه کلیدی SEGMENT از کلمه کلیدی ROW استفاده شده است.
ALTER TABLE orders ILM ADD POLICY ROW STORE COMPRESS ADVANCED ROW AFTER 3 DAYS OF NO MODIFICATION; |
- مثال چهارم:فرض می کنیم که جدول سفارشات پس از۹۰ روز بدون تغییرات باشد . وقتی دسترسی به این داده ها کمتر می شود و یا به اصطلاح “سرد” می شود سیاست ADO می تواند بطور خودکار داده ها را به فضای ذخیره سازی دیگر انتقال دهد. و وقتی که حتی ویرایش و پرس و جو روی داده خیلی کم می شود و دسترسی به داده ها در بازه زمانی طولانی اتفاق می افتد در این حالت داده ها را قدیمی فرض می کند و از روش فشرده سازی بایگانی (HCC ARCHIVE) برای فشرده سازی استفاده کرد.
ALTER TABLE orders ILM ADD POLICY COLUMN STORE COMPRESS FOR ARCHIVE HIGH SEGMENT AFTER 90 DAYS OF NO MODIFICATION; ALTER TABLE orders ILM ADD POLICY tier to slow_storage_ts; |
- مثال پنجم: در این مثال ایجاد جدول و نحوه پارتشن بندی آن را نشان می دهد.
CREATE TABLE invoices ( invoice_no NUMBER NOT NULL, invoice_date DATE NOT NULL, comments VARCHAR2(500) ) PARTITION BY RANGE (invoice_date) ( PARTITION invoices_2018_q1 VALUES LESS THAN (TO_DATE('01/04/2018', 'DD/MM/YYYY')) TABLESPACE slow_storage_ts, PARTITION invoices_2018_q2 VALUES LESS THAN (TO_DATE('01/07/2018', 'DD/MM/YYYY')) TABLESPACE slow_storage_ts, PARTITION invoices_2018_q3 VALUES LESS THAN (TO_DATE('01/09/2018', 'DD/MM/YYYY')) TABLESPACE medium_storage_ts ILM ADD POLICY TIER TO slow_storage_ts READ ONLY SEGMENT AFTER 6 MONTHS OF NO ACCESS, PARTITION invoices_2019_q4 VALUES LESS THAN (TO_DATE('01/01/2019', 'DD/MM/YYYY')) TABLESPACE medium_storage_ts ILM ADD POLICY TIER TO slow_storage_ts READ ONLY SEGMENT AFTER 6 MONTHS OF NO ACCESS, PARTITION invoices_2020_q1 VALUES LESS THAN (TO_DATE('01/04/2020', 'DD/MM/YYYY')) TABLESPACE fast_storage_ts ILM ADD POLICY TIER TO medium_storage_ts READ ONLY SEGMENT AFTER 3 MONTHS OF NO ACCESS, PARTITION invoices_2020_q2 VALUES LESS THAN (TO_DATE('01/07/2020', 'DD/MM/YYYY')) TABLESPACE fast_storage_ts ILM ADD POLICY TIER TO medium_storage_ts READ ONLY SEGMENT AFTER 3 MONTHS OF NO ACCESS ) ILM ADD POLICY ROW STORE COMPRESS BASIC SEGMENT AFTER 3 MONTHS OF NO ACCESS;
- در مثال بالا پارتیشن های invoices_2020_q1و invoices_2020_q2 که اطلاعات آنها از لحاظ تاریخ به روز می باشد و نیاز است که با سرعت بالا در دسترس باشد و یا به اصطلاح داده از نوع داغ می باشند. درtablespace ای بنام fast_storage_ts که روی دیسکها با سرعت بالا و هزینه بالا مانند SSDتعریف شده اند و یک سیاست ADOاز نوع انتقال داده یا طبقه ذخیره سازی (TIER)تعریف شده است. اگر بعد از سه ماه به اطلاعات پارتیشن مورد نظر دسترسی نباشد یعنی پرس و جو، گزارش و یا تغییری در رکوردها نباشد بطور خودکار و بدون دخالت مدیر پایگاه داده تمامی اطلاعات به روی tablespaceای بنام medium_storage_tsکه روی دیسکها با سرعت متوسط از نوع SAS تعریف شده است انتقال داده می شود و اطلاعات آن به فقط خواندی (Read Only ) تبدیل می شود.برای پارتیشن های invoices_2018_q3و invoices_2019_q4نیز همین اتفاق می افتد البته انتقال داده ها بعد از ۶ ماه بدون دسترسی به داده ها به روی tablespaceبنام slow_storage_tsکه روی دیسکها کم هزینه مانند SATAتعریف شده انتقال می یابد.به این روش انتقال داده ها از دیسکهای پر سرعت با هزینه بالا به دیسکهای سرعت متوسط با هزینه متوسط و سپس به دیسکهای کم سرعت با هزینه کمتر را طبقه بندی ذخیره سازی و یا Tieringمی گویند.
- ویژگی جدید در نسخه ۲۰c
- تمامی ویژگی های بالا در اوراکل نسخه ۱۲cآورده شده است، ویژگی جدید دیگری که بنام AIDیا Automatic Index Optimization برای خودکاری سازی انتقال ایندکس ها در نسخه ۲۰cآورده شده است.
- مثال برای ایندکس:
Alter table invoices add constraint pk_invoice_no primary key (invoice_no) using index tablespace fast_storage_idx_ts; ALTER INDEX invoices pk_invoice_no ILM ADD POLICY TIER TO slow_storage_idx_ts;
- نکته: البته در بعضی از SAN Storage ها این قابلیت Tiering با خرید لایسنس با هزینه بالا قابل پیاده سازی است و مستقل از پایگاه داده و هر برنامه کاربردی انجام می شود ولی این قابلیت در پایگاه داده اوراکل مستقل از قابلیتهای SAN Storage ها و بدون پرداخت هزینه لایسنس SAN Storage ها انجام می شود. و می توان ترکیبی از SAN Storage ها استفاده کرد.
- ادامه مراحل نهایی مدیریت چرخه حیات برنامه ریزی شده سازمان ، با رعایت معیارهای نهایی سیاست ADO ،داده ها اکنون به سطح HCC ARCHIVE HIGH فشرده می شوند و به فضای ذخیره سازی با هزینه کمتر منتقل می شوند.این اجازه می دهد تا داده های فعال در طبقه بندی عملکرد بالاتر باقی بمانند و همچنین اجازه می دهد تا داده های قدیمی، که به صورت آنلاین باقی مانده اند، همچنان توسط برنامه های کاربردی قابل دسترسی باشندروش ARCHIVE HIGH به طور معمول بالاترین سطح HCC را فراهم می کند و فشرده سازی در محدوده ۱۰ تا ۱۵ برابر و یا بیشتر را فراهم می کند.در این مثال ساده ILM پایگاه داده اوراکل به طور خودکار سیاست های ADO را ارزیابی می کند تا تعیین کند چه زمانی داده ها واجد شرایط انتقال به سطح فشرده سازی بالاتر هستند و چه وقت داده ها واجد شرایط انتقال به tablespace متفاوت هستند. این دسترسی به داده ها و عملکرد آنها را تضمین می کند، در حالی که ردپای ذخیره سازی را حتی بیشتر کاهش می دهد، بدون اینکه هیچ بار اضافی بر دوش مدیران پایگاه داده یاکارکنان مدیریت ذخیره سازی قرار دهد.
- توجه داشته باشید که فشرده سازی ستونی ترکیبی فقط با پایگاه داده اوراکل روی ماشین های Exadata یا با ذخیره سازی خاص اوراکل در دسترس است.
- نتیجه
- مدیریت چرخه زندگی اطلاعات (ILM) به سازمانها این امکان را می دهد تا بفهمند که چگونه داده های آنها با گذشت زمان قابل دسترسی است و فشرده سازی و ذخیره سازی طبقه بندی داده ها را مدیریت کنندویژگی های Heat Map و بهینه سازی خودکار داده های فشرده سازی پیشرفته با Oracle Database 12c به صورت جامع ارائه می شود و قابلیت های ILM خودکار باعث کاهش هزینه ها می شود در حالی که بیشترین عملکرد را در پایگاه داده خواهید داشت.